What is RisingWave?
RisingWave is a distributed SQL streaming database that enables simple, efficient, and reliable processing of streaming data.
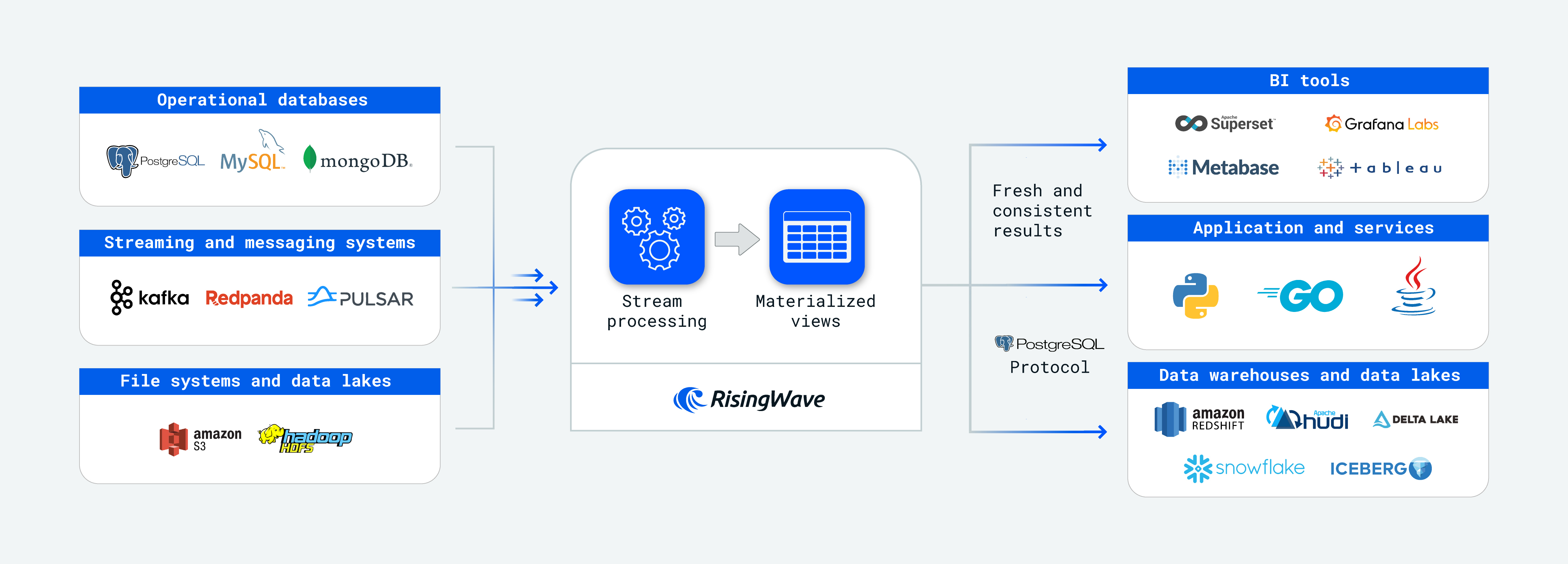
Why RisingWave for stream processing?
RisingWave specializes in providing incrementally updated, consistent materialized views — a persistent data structure that represents the results of stream processing. RisingWave significantly reduces the complexity of building stream processing applications by allowing developers to express intricate stream processing logic through cascaded materialized views. Furthermore, it allows users to persist data directly within the system, eliminating the need to deliver results to external databases for storage and query serving.
Compared to existing stream processing systems like Apache Flink, Apache Spark Streaming, and KsqlDB, RisingWave stands out in two primary dimensions: Ease-of-use and cost efficiency, thanks to its PostgreSQL-style interaction experience and Snowflake-like architectural design (i.e., decoupled storage and compute).
Ease-of-use
- Simple to learn
- RisingWave speaks PostgreSQL-style SQL, enabling users to dive into stream processing in much the same way as operating a PostgreSQL database.
- Simple to develop
- RisingWave operates as a relational database, allowing users to decompose stream processing logic into smaller, manageable, stacked materialized views, rather than dealing with extensive computational programs.
- Simple to integrate
- With integrations to a diverse range of cloud systems and the PostgreSQL ecosystem, RisingWave boasts a rich and expansive ecosystem, making it straightforward to incorporate into existing infrastructures.
Cost efficiency
- Highly efficient in complex queries
- RisingWave persists internal states in remote storage (e.g., S3), and users can confidently and efficiently perform complex streaming queries (e.g., joining dozens of data streams) in a production environment, without worrying about state size.
- Transparent dynamic scaling
- RisingWave's state management mechanism enables near-instantaneous dynamic scaling without any service interruptions.
- Instant failure recovery
- RisingWave's state management mechanism also allows it to recover from failure in seconds, not minutes or hours.
RisingWave's limitations
RisingWave isn’t a panacea for all data engineering hurdles. It has its own set of limitations:
- No programmable interfaces
- RisingWave does not provide low-level APIs in languages like Java and Scala, and does not allow users to manage internal states manually (unless you want to hack!). For coding in Java, Scala, and other languages, please consider using RisingWave's User-Defined Functions (UDF).
- No support for transaction processing
- RisingWave isn’t cut out for transactional workloads, thus it’s not a viable substitute for operational databases dedicated to transaction processing. However, it supports read-only transactions, ensuring data freshness and consistency. It also comprehends the transactional semantics of upstream database Change Data Capture (CDC).
- Not tailored for ad-hoc analytical queries
- RisingWave's row store design is tailored for optimal stream processing performance rather than interactive analytical workloads. Hence, it's not a suitable replacement for OLAP databases. Yet, a reliable integration with many OLAP databases exists, and a collaborative use of RisingWave and OLAP databases is a common practice among many users.
In-production use cases
Like other stream processing systems, the primary use cases of RisingWave include monitoring, alerting, real-time dashboard reporting, streaming ETL (Extract, Transform, Load), machine learning feature engineering, and more. It has already been adopted in fields such as financial trading, manufacturing, new media, logistics, gaming, and more. Check out Use cases.



