RisingWave vs. Apache Flink: Which one to choose?
We periodically update this article to keep up with the rapidly evolving landscape.
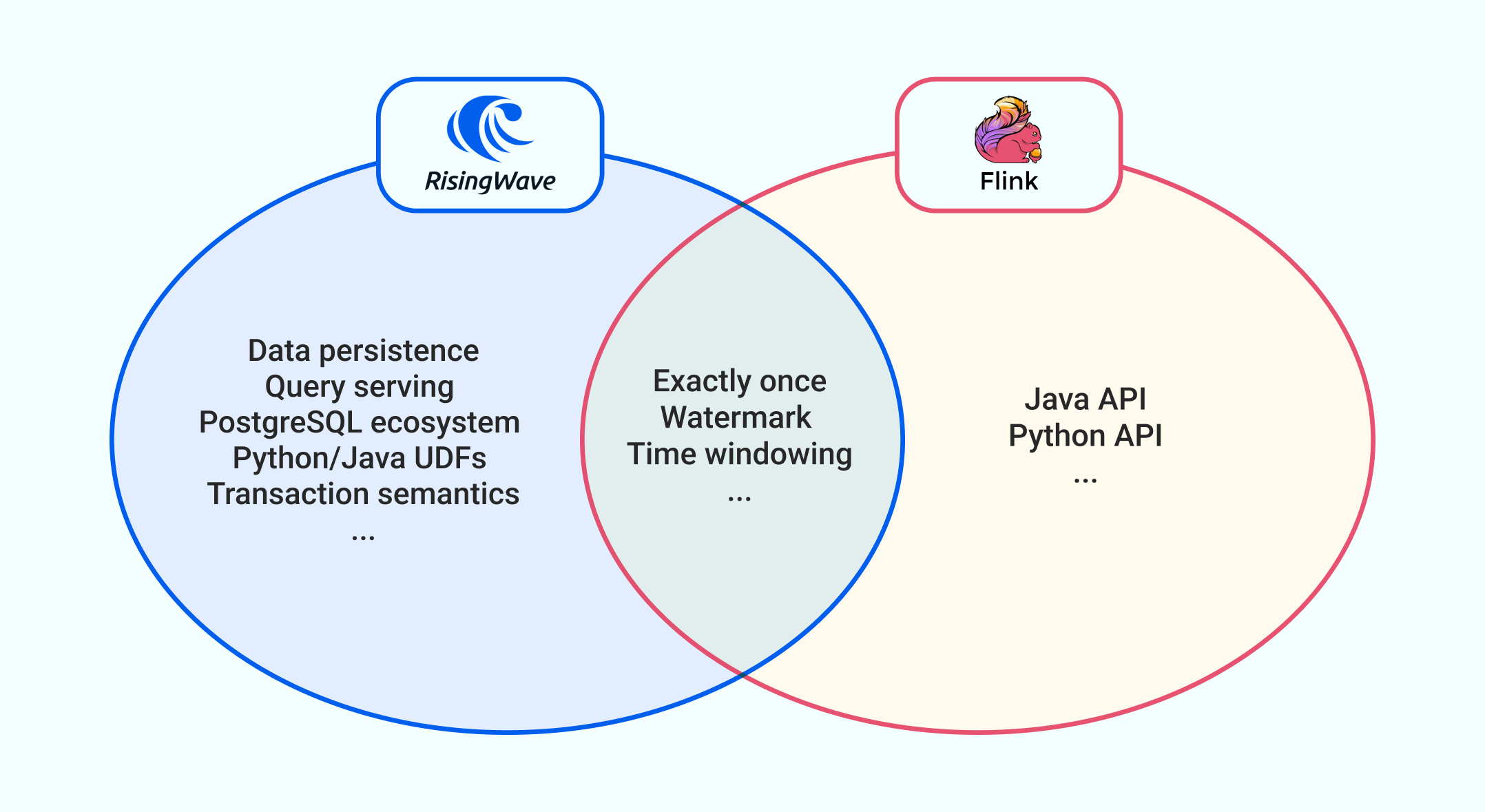
Summary
| Apache Flink | RisingWave | |
|---|---|---|
| Version | 1.17 | Latest version |
| License | Apache License 2.0 | Apache License 2.0 |
| System category | Stream processing framework | Streaming database |
| Real-time pipeline orchestration | Complex | Simple |
| Architecture | MapReduce-style | Cloud-native |
| Native API | Java, Scala, Python, SQL | SQL |
| Client libraries | None | Java, Python, Node.js, and more |
| State management | RocksDB in local machine; periodically checkpointed to S3 | Native storage persisted in S3 or equivalent storage |
| Query serving | DataSet and Table API, Apache Flink Table Store, batch mode execution | Support concurrent ad-hoc SQL query serving |
| Correctness | Support exactly-once semantics and out-of-order processing | Support exactly-once semantics, out-of-order processing, and snapshot read |
| Integrations and tooling | Big-data ecosystem | Big-data ecosystem, cloud ecosystem, and PostgreSQL ecosystem |
| Learning curve | Steep | Extremely shallow |
| Maintenance cost | High | Low |
| Performance cost | High | Low |
| Typical use cases | Streaming ETL, streaming analytics | Streaming ETL, streaming analytics, online serving |
Introduction
Apache Flink is a distributed stream processing framework; RisingWave is a distributed SQL streaming database.
Apache Flink
Apache Flink is a popular open-source distributed stream processing framework that was introduced in 2011. Flink features a distributed Java-based dataflow engine that supports parallel, pipelined, and iterative execution of both batch and stream processing programs. Additionally, Flink offers fault-tolerant processing with exactly-once semantics. Users can write programs in Java, Scala, Python, and SQL on a large data cluster. Flink also provides dozens of connectors to popular systems, making it easy for users to connect to existing data storage systems.
RisingWave
RisingWave is an open-source distributed SQL database designed for stream processing. Initiated in late 2020, RisingWave focuses on reducing the complexity and cost of building real-time applications. Built from scratch using Rust, RisingWave is well-optimized for supporting high-throughput and low-latency stream processing in the cloud. It guarantees data consistency and completeness, even if node failure occurs. As a database system, RisingWave has its own storage for persisting data and serving user-initiated queries. It also offers dozens of connectors to mainstream systems, allowing users to connect to external systems freely.
Real-time pipeline orchestration
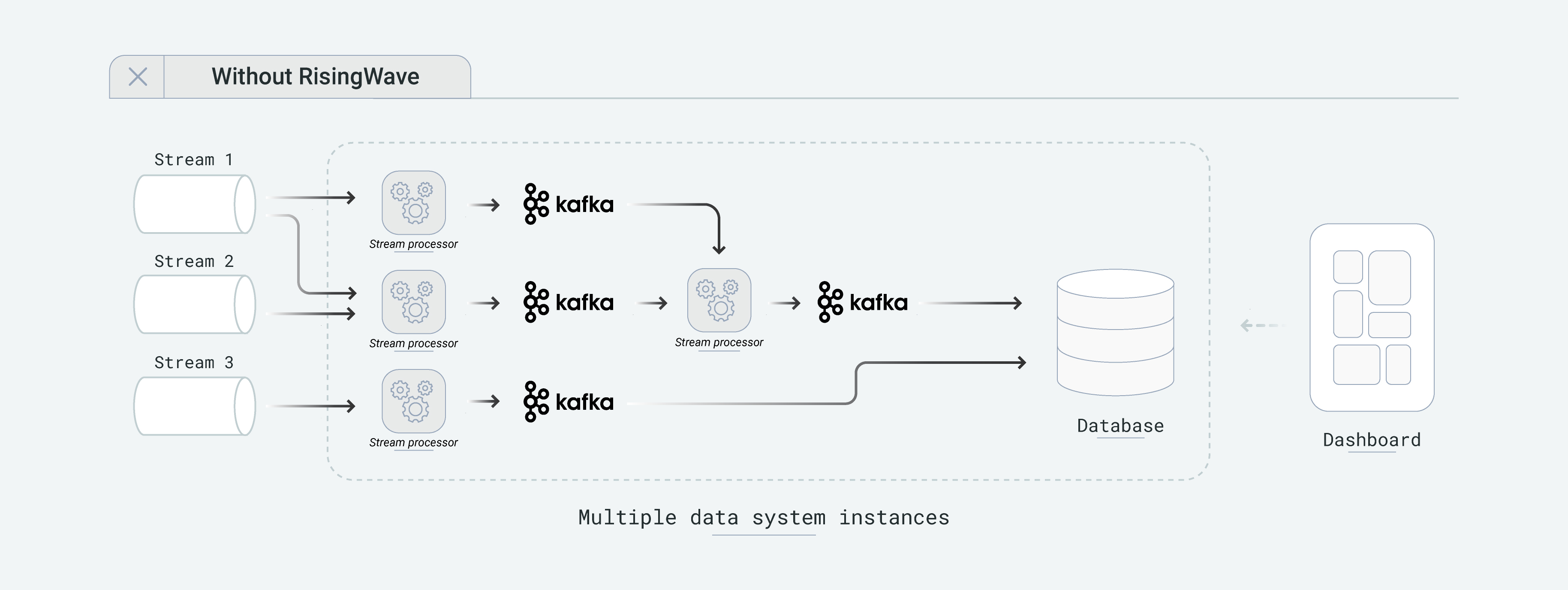
When developing applications using Apache Flink, developers need to manage multiple systems and handle the consistency relationships between them. When using RisingWave, developers only need to manage a single system and do not need to consider any relationships between different system components.
When developing applications using Apache Flink, users need to connect multiple instances of a stream processing engine with multiple instances of message queues to express complex logic. To query the results, users must export the stream processing results to a dedicated downstream database and perform queries there. This architecture is complex, incurs high operational costs, and requires users to take responsibility for the consistency of computation results across systems.
The diagram below illustrates the situation when building applications using traditional stream processing engines like Apache Flink. Developers need to manage multiple systems and handle the consistency relationships between them.
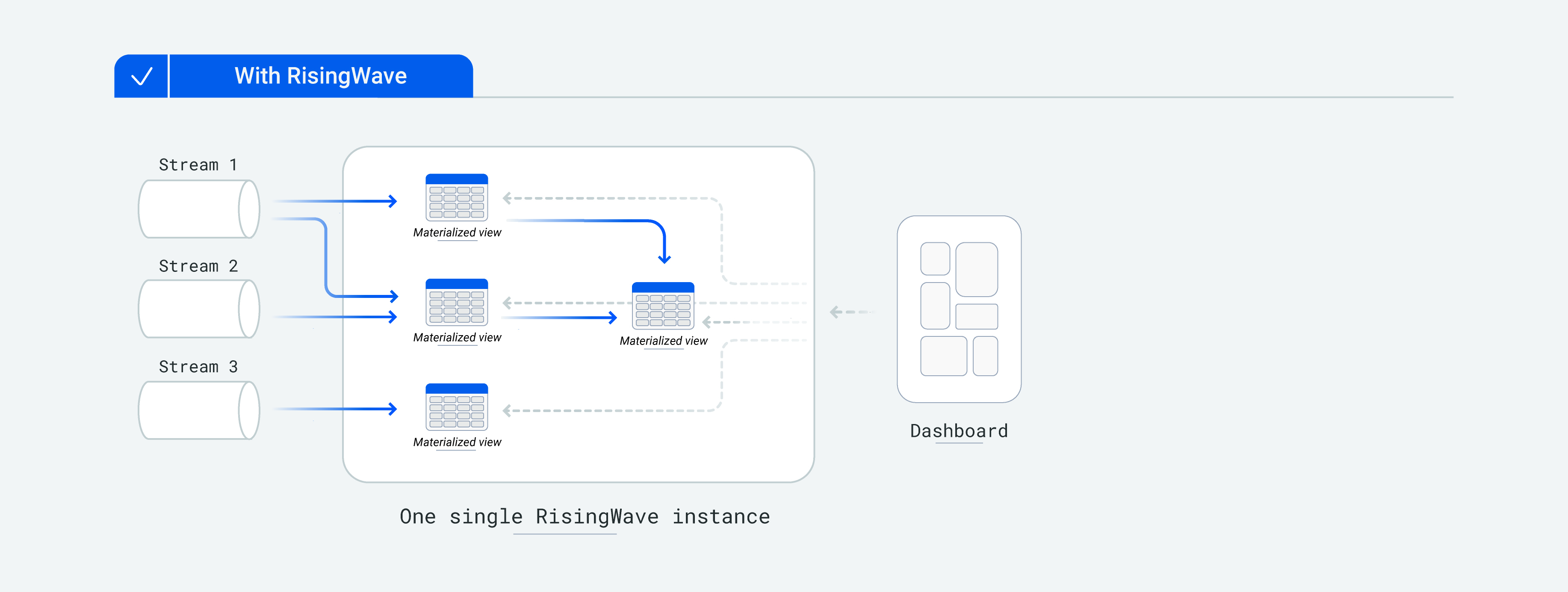
When using RisingWave, users only need to focus on constructing materialized views and can reduce development complexity by splitting complex logic into multiple cascading materialized views. RisingWave guarantees the consistency, persistence, and high concurrent query access of materialized views. Users only need to manage a RisingWave cluster, as RisingWave ensures the consistency between different materialized views.
The diagram below illustrates the situation when developing applications using the RisingWave stream database. Developers only need to manage a single system and do not need to consider any relationships between different system components.
Architecture
Apache Flink adopts a big-data style, coupled-compute-storage architecture that is optimized for scalability; RisingWave in contrast implements a cloud-native, decoupled compute-storage architecture that is optimized for cost efficiency.
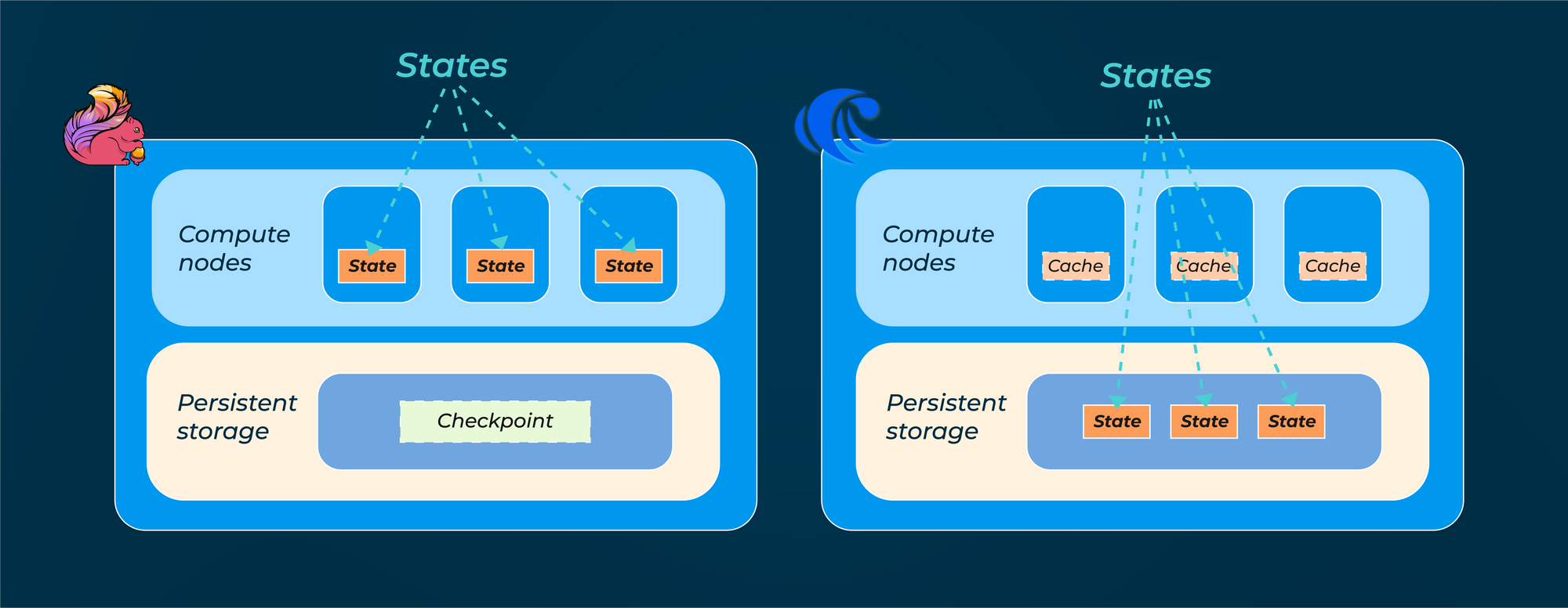
As an open-source project born during the Hadoop-dominant big-data era, the architecture of Flink was heavily influenced by the MapReduce paradigm. Specifically, Flink achieves parallel and distributed execution by dividing a streaming task into multiple parallel instances, each processing a subset of the task's input data. While this compute-storage-coupled architecture enables Flink to achieve high parallelism and scalability, it can also result in high execution costs.
RisingWave was created during the cloud era. By adopting a modern compute-storage-decoupled architecture, RisingWave achieves better scalability and flexibility. Each component can be configured differently and scaled independently, leading to improved cost-efficiency and performance. The new architecture also allows each component to be optimized separately, reducing resource waste and avoiding task overload.
Native API
Apache Flink offers both low-level Java, Scala, and Python APIs and a high-level SQL interface; RisingWave in contrast offers PostgreSQL-style SQL as the user interface.
Apache Flink implements a flexible and powerful programming model based on the concept of streams and transformations. In Flink, users define data processing pipelines as directed acyclic graphs (DAGs) of transformations, which can be chained together to form complex data processing workflows. The native API supports this programming model in Java, Scala, and Python, enabling developers to create their streaming pipelines in these languages. Flink’s programming model allows for fine-grained control over data processing, which can lead to better performance and more efficient use of resources. However, the downside is that the programming model of Flink can be difficult to learn and use. Additionally, Flink provides a SQL layer on top of its kernel, which users can utilize to process streaming data.
RisingWave is a SQL streaming database that offers PostgreSQL-style SQL to its users. This means that users can perform stream processing in the same way as they would using PostgreSQL. Although RisingWave does not provide low-level APIs, it supports user-defined functions (UDFs) in both Python and Java, with which users can express complex logic.
Client libraries
Apache Flink is a programming framework that does not support any language clients. To use Apache Flink, users must either write Java/Scala/Python programs or use Flink’s own SQL client.
RisingWave is compatible with the PostgreSQL wire protocol and can work with the majority of PostgreSQL's client libraries. This means that RisingWave can communicate in any programming language that is supported by the PostgreSQL driver, such as Java, Python, and Node.js. Additionally, users can interact with RisingWave using psql, the official PostgreSQL terminal.
State management
Apache Flink uses RocksDB to maintain local states, which are periodically checkpointed to remote storage such as S3; RisingWave by design is a database and has its own storage to persist internal state and data in S3 or equivalent storage services.
State management is an important aspect of stream processing systems. It refers to the ability of the system to track and manage the internal computation state so as to support elastic scaling and failure recovery.
As a stream processing framework, Apache Flink was not optimized for persisting data. It uses RocksDB to manage internal states in each machine, and periodically sends the internal states to remote persistent storage for checkpointing purposes. This strategy works for scenarios where the state size is small. However, when supporting large-state scenarios (such as maintaining a 7-day windows or joining multiple data streams), Flink can crash directly or confront performance degradation due to excessive page swapping.
RisingWave uses its own cloud-native storage system, called Hummock, to persist materialized views and internal states in stateful stream executors to cloud storage services (specifically, all S3-compatible services). Similar to an LSM-tree, Hummock persists data in tiered storage and is optimized for bulk writes. In RisingWave, data persistence is triggered by a checkpoint-style coordination process. Each executor receives barrier messages from its upstream executors and increments the delta of state updates into Hummock. This mechanism enables RisingWave to support stream processing that requires extra-large state management.
Query serving
Apache Flink was not designed for serving ad-hoc queries; RisingWave by design is a database and can serve concurrent ad-hoc queries.
The batch processing engine in Flink shares similar design principles with its stream processing engine, allowing it to leverage many of the same optimizations and features. When running batch queries in Flink, users can use either the DataSet API or the Table API, both of which provide a high-level interface for writing batch processing jobs. The DataSet API allows users to write batch processing jobs using Java or Scala, while the Table API provides a SQL-like language called FlinkSQL for querying and manipulating batch data.
In 2022, Flink launched the Table Store project (now renamed Apache Paimon) to enhance its ability to query streaming computation results or intermediate states. Table Store mainly adopts a columnar storage format and is designed to address the lack of support for streaming systems in data lake products such as Iceberg. The design of Table Store reflects its main use in offline analysis scenarios and is not suitable for high-concurrency online service queries.
RisingWave enables users to query both materialized views and the internal states of stateful stream operators using PostgreSQL-style SQL. The platform has a built-in batch query engine that utilizes modern database technologies to optimize performance. The batch engine offers two modes: local and distributed. The local mode is designed for processing point queries with high concurrency, while the distributed mode is for processing large volumes of data in parallel. This allows users to rely on RisingWave for serving concurrent SQL queries, minimizing the need for additional external systems and reducing costs.
Correctness
Apache Flink delivers consistent and complete results to downstream systems; RisingWave offers even higher correctness guarantee, as it not only ensures consistency and completeness, but also provides consistent snapshots for any data access.
For stream processing systems, the definition of correctness is two-fold:
- Consistency. Every single data event will be processed once and only once, even if any system failure occurs. This is also known as exactly-once semantic.
- Completeness. Even if a data stream arrives out of order, the results will ultimately be in order.
Both RisingWave and Apache Flink are stream processing systems that guarantee consistency and completeness. Specifically, both systems guarantee exactly-once semantics via a consistent checkpoint algorithm. They also introduce the concept of watermarks to infer the completeness of out-of-order data.
RisingWave is not only a stream processing platform, but also a streaming database. It ensures that all data accesses reach a consistent snapshot of the stored data. This means that users are guaranteed to always see consistent results without any confusion.
Integrations and tooling
Apache Flink offers dozens of connectors to the systems in the big data world; in contrast, RisingWave can be well integrated into not only big data and cloud ecosystems but also the PostgreSQL ecosystem.
Both RisingWave and Apache Flink are designed for large-scale stream processing and have comprehensive support for big data ecosystems. They both support ingesting streaming data from message queues like Kafka and Pulsar. Additionally, they can sink processed data to downstream databases or data warehouses such as MySQL, Redis, Redshift, and Snowflake.
RisingWave differs from Apache Flink in that it was specifically designed for the cloud ecosystem. This means that RisingWave can be easily integrated with cloud services like Confluent Cloud, DataStax, and Grafana Cloud. Additionally, RisingWave supports built-in secure connections to upstream sources. Users can create a PrivateLink across VPCs directly using any RisingWave client.
RisingWave can function as both a stream processing system and a database system. As a database system, it is compatible with PostgreSQL clients, making it a natural fit for the PostgreSQL ecosystem. Users can program in different languages such as Python, Java, and Node.js using existing libraries. Additionally, users can easily find tools that work with RisingWave, such as DBeaver.
For a complete list of RisingWave integrations, see Integrations.
Learning curve
Apache Flink has a steep learning curve as it offers more details in low-level control; In contrast, RisingWave has a minimal learning curve and is simple and easy to use.
Apache Flink has a steep learning curve. The programming model of Flink is based on more complex concepts, such as data streams, data sets, and transformations, which may take some time to master. Flink also has a more complex architecture, with a number of different components that must be manually configured and managed.
RisingWave simplifies stream processing by allowing users to interact with it using SQL, just like interacting with PostgreSQL. The platform introduces only a minimal set of stream processing concepts, such as sources, sinks, and windows. As a result, RisingWave is an excellent choice for users new to stream processing or those who need to quickly prototype and deploy stream processing applications.
Maintenance cost
Apache Flink has a high maintenance cost due to its complex configuration; RisingWave has a much lower maintenance cost as it extensively leverages hosted cloud services.
Apache Flink has a high maintenance cost. Setting up and configuring a Flink cluster require a significant amount of time and effort due to its inherent architectural complexity. Additionally, since Apache Flink employs a compute-storage-coupled architecture, a cluster must be reconfigured whenever a single component runs out of resources. This means that developers must repeatedly invest effort in response to online fluctuating workloads.
On the other hand, RisingWave has a much lower maintenance cost. It aims to minimize the setup and configuration processes required. Users can easily deploy RisingWave in their local environment using out-of-the-box developer tools. Additionally, RisingWave extensively leverages hosted cloud services to reduce maintenance costs. The built-in elasticity of cloud services allows RisingWave to scale in and out at a low cost.
Performance cost
To achieve the target performance, Apache Flink is at a higher cost due to its heavy architectural design; On the other hand, RisingWave is much more cost-efficient with its disaggregated architecture.
Apache Flink is designed for high-performance and low-latency processing of large-scale data in real-time. However, its compute-storage-coupled architecture can require a significant amount of computational resources. Shortages in either computation or storage capacity can lead to system bottlenecks. Additionally, the JVM runtime used by Apache Flink can introduce significant overhead in terms of memory consumption.
In contrast, RisingWave focuses on low-cost stream processing on the cloud and, in most cases, achieves better cost efficiency than Apache Flink. Several factors contribute to the cost efficiency of RisingWave.
RisingWave adopts a compute-storage-decoupled architecture that allows the system to dynamically provision resources for different components based on the workloads.
As a streaming database, RisingWave implements the concept of materialized views, which provides users with opportunities to reuse computation resources across different stream processing pipelines by maintaining and sharing intermediate computation results.
RisingWave’s Rust-based implementation achieves high performance with minimal overhead in computation and memory usage.
Typical use cases
Apache Flink is suitable for comprehensive streaming ETL and streaming analytics applications; RisingWave not only supports streaming ETL and analytics applications, but can also do online serving with its built-in capability.
Apache Flink is well-suited for comprehensive streaming ETL tasks and streaming analytics. It offers a powerful set of APIs and libraries for connecting to data sources, performing transformations, windowing, complex event processing, stateful stream processing, and sinking data to external systems.
However, to build such a pipeline and make use of transformed data, you need to deploy both Apache Flink and a downstream online serving database.
RisingWave offers not only streaming ETL and streaming analytics, but also online serving capabilities through its built-in batch query engine. By defining materialized views, analytical results of input streams can be gathered and served directly in RisingWave. Its distributed frontend cluster supports high-concurrency queries with horizontal scalability.
Compared to Flink SQL, RisingWave has more comprehensive support for SQL features. For example, RisingWave supports the streaming execution of the complete TPC-H query and can ensure the correctness of the results. For time window queries, Flink SQL restricts the time column to be the watermark column of the data source, while RisingWave has no such limitations.
How to choose?
So, which one should you choose? The answer to this question depends on your specific use case and requirements.
Both solutions excel in executing complex, large-scale stream processing data pipelines across clusters. The decision ultimately depends on the developer's expertise and operational skills required to manage the solution efficiently.
For an easy on-ramp to real-time processing, RisingWave is an excellent choice. It offers a simple, cost-efficient, SQL-based solution that can be quickly deployed. This makes it ideal for data-driven businesses of any size that require real-time processing capabilities.
Alternatively, if you require low-level API access that integrates seamlessly into your JVM-based technical stack, Apache Flink is the preferred option. Flink is well-suited for businesses with large teams that prefer building custom solutions tailored to their specific needs.



